After moving an application from an EC2 fleet to a Kubernetes cluster hosted on AWS EKS, we started to face some errors due to DNS resolution. The errors where more during intensive usage of the app (bellow an example of the errors we were facing).
PDOException: Noticed exception 'PDOException' with message 'SQLSTATE[HY000] [2002] php_network_getaddresses: getaddrinfo failed: Temporary failure in name resolution'
We started by checking the overall health of the cluster. Started by evaluating the CoreDNS pods resources and moving forward to the resource usage from each node (bandwidth, CPU, memory). With all those measurements one thing was clear, the problem apparently is not directly related to physical resource usage. Once we knew that we were free of resource starvation, got inside one of the application pods and performed some DNS queries continuously, it was confirmed the DNS service was in an intermittent working state.
In contact with AWS Support we got the confirmation:
You are being throttled!
Observability on CoreDNS
One of the worst things that can happen when debugging something is the lack of observability in a service. It’s highly recommended that you collect metrics and analyse to better understand what they mean. To expose CoreDNS metrics, you need to enable the Prometheus plugin CoreDNS. To export them and then make your monitoring system to gather them.
CoreDNS also has a plugin for logging, enable logging on CoreDNS will be quite useful since it will help us to understand which DNS query got each response, but for this, I highly recommend you to use some log aggregator to ingest all these logs.
Having this in place, we will be able to observe fundamental metrics from our CoreDNS service, such as:
- Total query count
- DNS request duration
- DNS response code
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
log . {combined} {
class denial error
}
}
If you have the reload plugin enabled, the CoreDNS will automatically reload the config, otherwise, you will need to restart each pod.
A party of unreachable backends
Once the logging and the metrics were enabled, we opened the log of one of the pods. The behaviour for some queries matched the behaviour reported by the support:
...
myamazingapp.eu-west-1.elb.amazonaws.com.eu-west-1.compute.internal. AAAA: unreachable backend: read udp 10.162.50.75:53995->10.162.50.2:53: i/o timeout
...
Technically, you can get throttled if you do a lot of requests. What if most of the requests are being executed from a few parts of the cluster nodes?
kubectl get pods -n kube-system -o wide | grep corends | awk '{print $7}' | sort | uniq -c
One thing was confirmed, around 50% of the CoreDNS pods were placed into a single node.
Since we need to prevent the allocation of multiple CoreDNS pods in the same cluster node, we configured an AntiAffinity rule on CoreDNS deployment config the. The HPA (Horizontal Pod Autoscaling) was still needed for the times with more traffic, so since we were using a ReplicaSet, we kept it.
...
eks.amazonaws.com/component: coredns
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: eks.amazonaws.com/component
operator: In
values:
- coredns
topologyKey: kubernetes.io/hostname
...
NXDOMAIN’s were also at the party
Once the metrics were available, we discovered a huge number of NXDOMAIN’s were visible. In a situation that you highly depend on the upstream DNS servers this can become an issue, due to the throttling.
[INFO] 10.*.*.17:43607 - 37066 "A IN ssm.eu-west-1.amazonaws.com.kubernetes-external-secrets.svc.cluster.local. udp 91 false 512" NXDOMAIN qr,aa,rd 184 0.000053579s "0"
[INFO] 10.*.*.17:57091 - 12032 "A IN ssm.eu-west-1.amazonaws.com.cluster.local. udp 59 false 512" NXDOMAIN qr,aa,rd 152 0.000111246s "0"
[INFO] 10.*.*.17:57833 - 16358 "A IN ssm.eu-west-1.amazonaws.com.svc.cluster.local. udp 63 false 512" NXDOMAIN qr,aa,rd 156 0.000057119s "0"
[INFO] 10.*.*.17:60412 - 53922 "A IN ssm.eu-west-1.amazonaws.com.eu-west-1.compute.internal. udp 72 false 512" NXDOMAIN qr,rd,ra 72 0.000905037s "0"
[INFO] 10.*.*.17:43959 - 61205 "A IN ssm.eu-west-1.amazonaws.com.eu-west-1.compute.internal. udp 72 false 512" NXDOMAIN qr,rd,ra 72 0.000801096s "0"
Let’s first understand some DNS responses
In yellow, you can find what I think the most important responses to this use case.
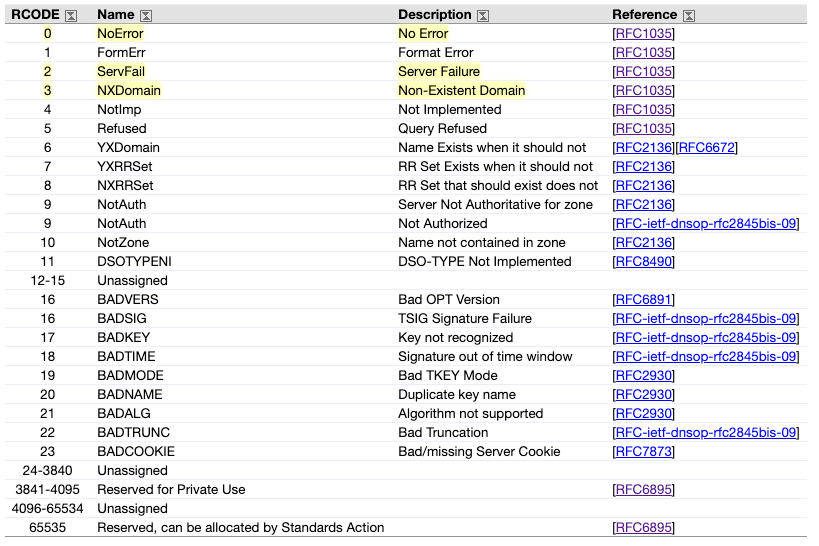 Full RFC here
Full RFC here
- NoError - It means that the query was properly resolved and returned.
- ServFail - The server failed to resolve the requested record.
- NXDomain - The domain doesn’t exist
NXDOMAIN’s deserves a bit more of explanation so we can understand the impact of it.
Step 1 - Application queries for a non existing DNS record
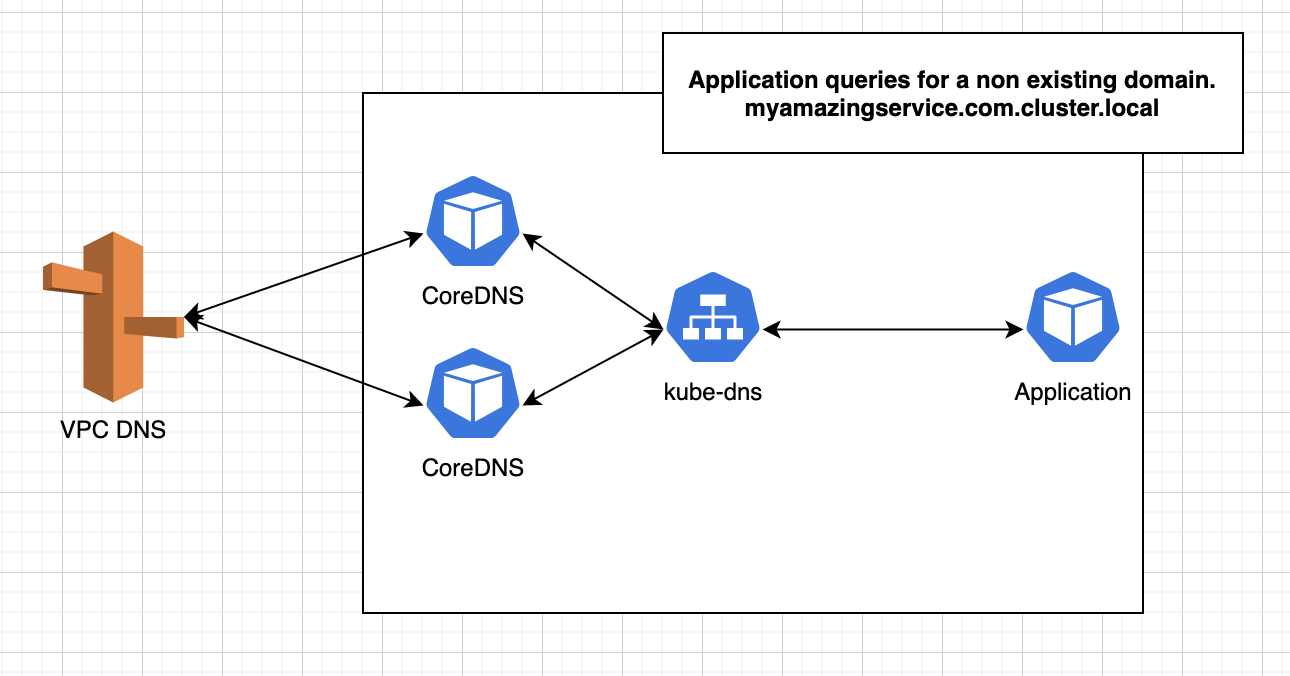
Step 2 - CoreDNS can’t resolve the record or get it from cache
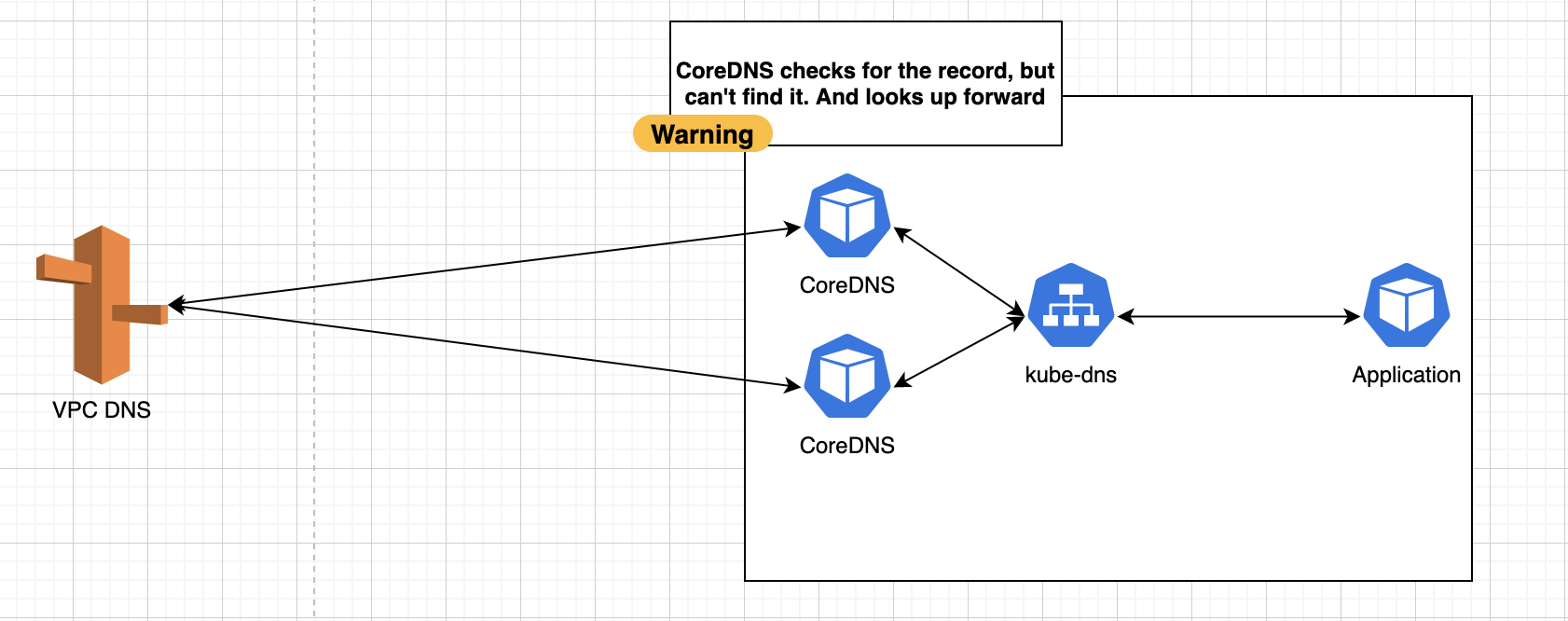
Step 3 - AWS DNS also can’t resolve the DNS query, so an NXDOMAIN response is returned
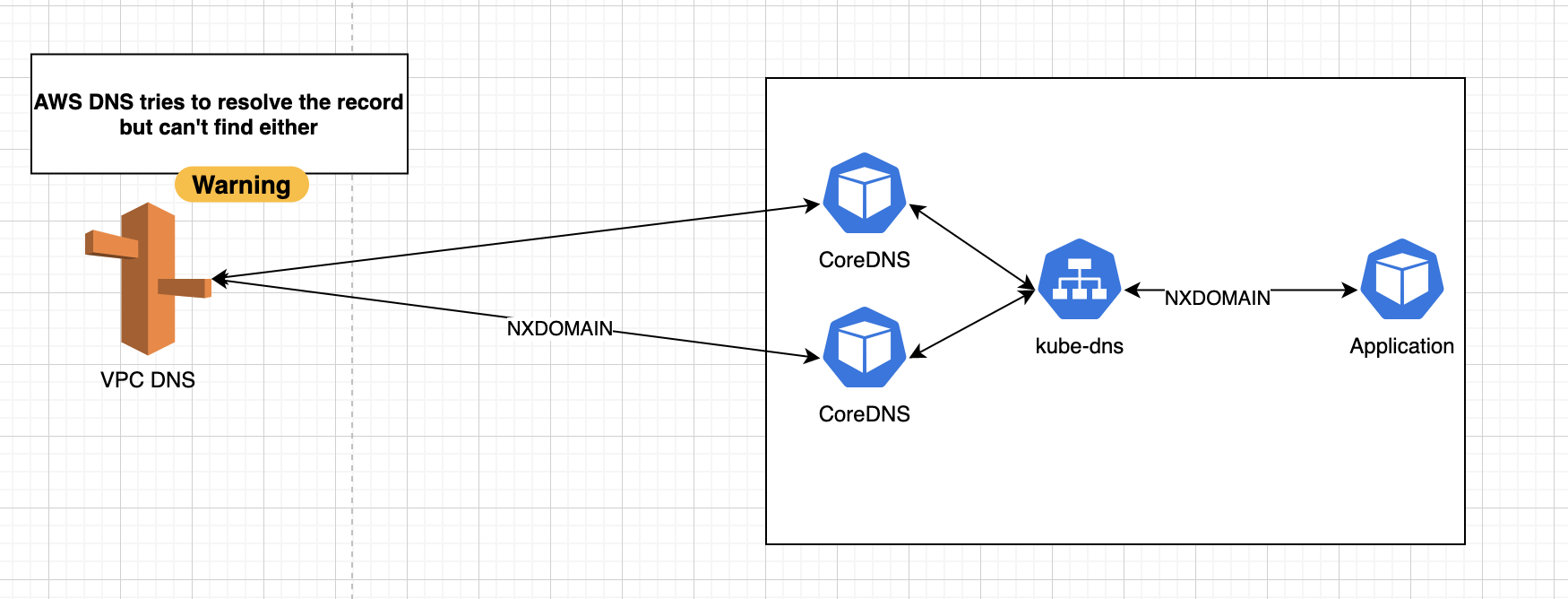
The problem here starts with the number of NXDOMAIN responses that are generated, with the value for NDOTS configured by Kubernetes deployment configuration to 5 which overwrites the default value from resolve.conf which is 1.
ndots is a configuration located in resolv.conf, which usually is configured by the DeploymentConfig for a given pod. For instance, if you look into an application resolv.conf you will find something like this:
nameserver 10.160.20.1
search myamazingappnamespace.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
Imagine that you run a DNS query to metadata.google.com, this means a query with two dots, since 2 is less than 5 dots, the DNS resolver will also attempt to run the DNS query metadata.google.com with all the domains in the list
- myamazingapp.svc.cluster.local
- svc.cluster.local
- cluster.local
Most of these queries will result in an NXDomain response from the DNS server. In the end, the application ends up querying AWS DNS servers for nonexisting records.
The queries resulting in NXDOMAIN can be query * n, where n is the number of domains in resolv.conf.
With this, the amount of NXDOMAIN responses can turn up to be huge since the query will follow the domain list configured in resolv.conf.
Let’s find who’s triggering NXDOMAIN queries
Once you have the logs being exported to a log aggregator, it is quite easy to identify what is the namespace of the application that is generating the requests resulting in NXDOMAIN replies.
- Since
.svc.cluster.localis one of the domains placed in theresolve.confof almost every application by the deployment config, lets query in the logs generated by CoreDNS for records containing this domain and theNXDOMAINword. This way we can have an estimation about how manyNXDOMAINreplies are being generated due to the number ofndots. In the example above you can see a query for AWS Cloudwatch Logs:
fields @timestamp, @message
| filter log ~= /NXDOMAIN/ and log ~= /.svc.cluster.local./
| sort @timestamp desc
| limit 20
Applications that have configured a high number of ndots, also query for a domain containing its namespace name on it, for example ssm.eu-west-1.amazonaws.com.eu-west-1.compute.internal., so it reduces a lot the result that we need to look into.
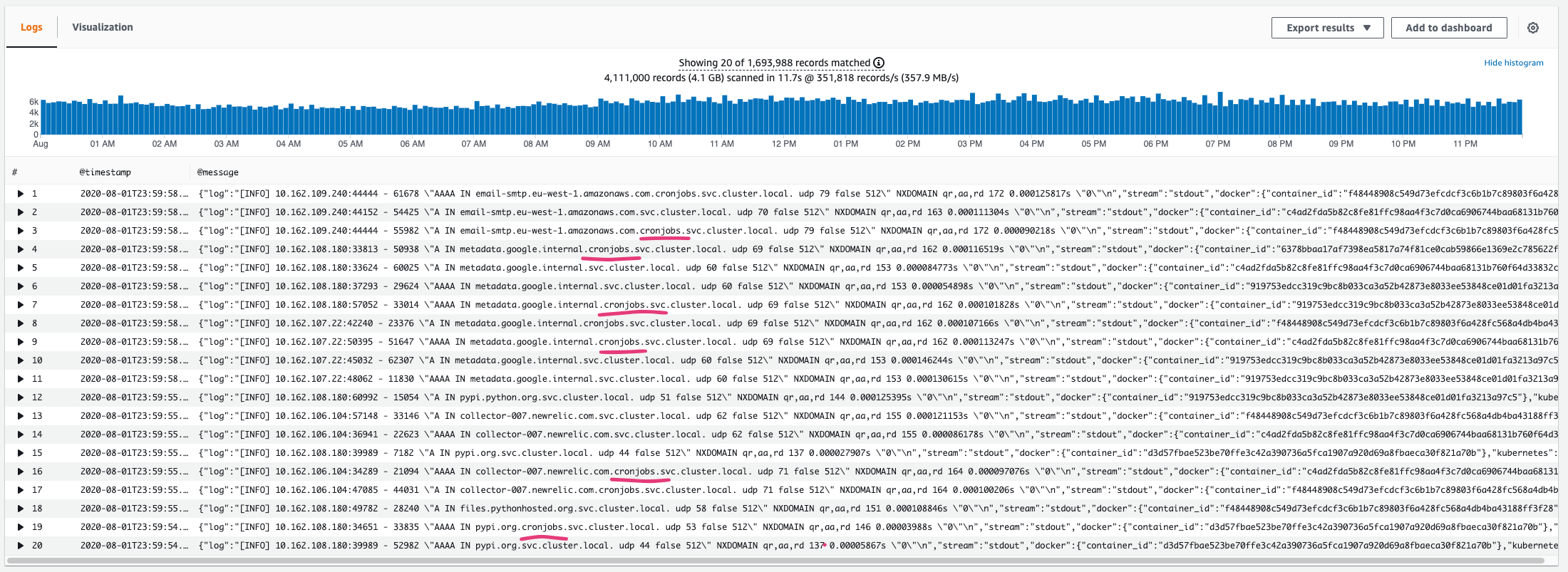
- Let’s refine a bit more our query, to look specifically for
NXDOMAINrecords on this specific domainssm.eu-west-1.amazonaws.com.eu-west-1.compute.internal..
fields @timestamp, @message
| filter log ~= /NXDOMAIN/ and log ~= /ssm.eu-west-1.amazonaws.com.eu-west-1.compute.internal../
| sort @timestamp desc
| limit 20
- Check the applications in the namespace and evaluate with the owner if you can patch the deployment config with a
ndots: 1
...
spec:
dnsConfig:
options:
- name: ndots
value: "1"
...
Once the ndots is set to 1, the number of NXDOMAIN response decreased drastically.

Conclusion
In an environment with such a high number of QPS not only special attention to the NXDOMAIN’s is needed, but also to the configuration of ndots shown to help a lot.
Even if we can reach a cache hit ratio on the DNS queries of 99.99%, HPA might also be needed on CoreDNS. Since replies from the cache are not for free, and in this use case associate the deployment config with an AntiAffinity rule also helped distributing the CoreDNS pods between all nodes and avoiding throttling from the upstream DNS (since the quota is per EC2 instance).
A big part of this behaviour can be highly improved by using NodeLocal DNSCache. But unfortunately, this feature is only available on Kubernetes 1.18 as stable and the cluster we operated was in 1.14. This feature also can improve the latency on queries resolution while resolving from cache since the requests don’t leave the cluster node.

References
- RFC-6895
- DNS Query Types and Application Troubleshooting - Thierry Notermans
- What happens when you update your DNS? - Julia Evans
- Pod DNS Config
- resolv.conf
- DNS, Network Sorcery